Washington Post story. You can no longer put the CDs you BOUGHT onto your iPod.
Update: ok, apparently the story is wrong. Still, the RIAA is evil…
Technorati Tags: RIAA, digital music
Washington Post story. You can no longer put the CDs you BOUGHT onto your iPod.
Update: ok, apparently the story is wrong. Still, the RIAA is evil…
Technorati Tags: RIAA, digital music
In C#, If you need to unit test a class that fires an event in certain circumstances (perhaps even asynchronously), you need to handle a little more than just running some code and doing the assertion. You have to make sure your unit test waits for the event to be fired. Here’s one naive way of doing it, a WRONG way:
1: private bool statsUpdated = false;
2: private ManualResetEvent statsUpdatedEvent = new ManualResetEvent(false);
3:
4: [Test]
5: public void CheckStats()
6: {
7: BrickDatabase db = new BrickDatabase(tempFolder, maxCacheAge);
8:
9: statsUpdated = false;
10: statsUpdatedEvent.Reset();
11:
12: db.InventoryStatsUpdated += new EventHandler(db_InventoryStatsUpdated);
13: db.DoSomethingThatFiresEvent();
14:
15: statsUpdatedEvent.WaitOne();
16:
17: Assert.IsTrue(statsUpdated);
18: }
19:
20: void db_InventoryStatsUpdated(object sender, EventArgs e)
21: {
22: statsUpdated = true;
23: statsUpdatedEvent.Set();
24: }
There are a number of things wrong with this:
Here’s a better way of doing it, using anonymous methods in C# 2.0:
1: [Test]
2: public void CheckStats()
3: {
4: BrickDatabase db = new BrickDatabase(tempFolder, maxCacheAge);
5: bool statsUpdated = false;
6: ManualResetEvent statsUpdatedEvent = new ManualResetEvent(false);
7:
8: db.InventoryStatsUpdated += delegate
9: {
10: statsUpdated = true;
11: statsUpdatedEvent.Set();
12: };
13:
14: db.DoSomethingThatFiresEvent();
15:
16: statsUpdatedEvent.WaitOne(5000,false);
17:
18: Assert.IsTrue(statsUpdated);
19: }
Improvements?
Power. Electricity. The Holy Grail of modern technology.
I say this because the information revolution completely depends on electricity, whether it’s batteries, hybrid motors, or the grid. Everything we do depends on converting some naturally occurring resource into power to drive our lives.
I was thinking about power recently while watching an episode of Star Trek: The Next Generation. Everything they do depends on an infinite (or nearly so) source of energy. Their warp core powers the ship for a 20-year mission. Each device they have is self-powered. From what? Do they need recharging? I imagine not, but it’s been a while since I’ve read the technical manual.
In any case, much of that world (and other Sci-Fi worlds) depends on powerful, long-lasting, disconnected energy sources. For one example, think of the energy required to power a laser-based weapon. And it has to fire more than once.
The truth is that having such a power source is more than world-changing. It has the potential to completely rebuild society from the ground up. If you think about it, much of the world’s conflict is over sources of energy. Authority and power is derived from who controls the resources. If energy was infinitely available, it would be infinitely cheap (at least in some sense). I almost think it would change society from being so focused on worldly gain, to more on pursuit of knowledge, enlightenment, and improvement. We wouldn’t have to worry about how to get from one place to another, or who has more oil, or what industries to invest energy resources in. So much would come free.
When I speak of “infinite” power, don’t take it literally. What I mean is “So much to be practically unlimited.”
Of course there are different types of infinities:
And there are a few other requirements we should consider:
It’s nice to dream about such things…
With such a power source the energy economy of devices that we have to pay such close attention to now goes out the window. Who cares how much energy it uses if there’s an endless amount to go around (and since we’ve already established that the energy source is non-destructive and highly-efficient, environmental factors don’t enter in). There would be no need for efficiency until you started bumping up the boundaries of how much power you needed.
Anybody who’s taken high school or college mathematics know how phenomenal exponential growth is. Even if the exponent is very, very small, it eventually adds up. With that in mind, look at this quick-and-dirty chart I made in Excel, plotting the growth in hard drive capacity over the years. [source: http://www.pcguide.com/ref/hdd/hist-c.html]
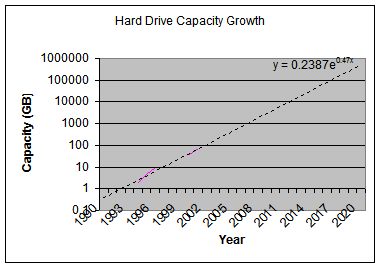
Ok. it’s ugly, but notice a few things:
Also, this doesn’t really take into account multiple-hard drive storage schemes like NAS, RAID, etc. Right now, it’s quite easy to lash individual storage units together into packages such as those for more space, redundancy, etc. I’ll ignore that ability for now.
So 2020: that’s 12 years from now. We can expect to have a petabyte in our computers. That’s a LOT of space. Imagine the amount of data that can be stored. How about every book ever written? How about all your music, high-def DVDs, ripped with no lossy compression?
Tools such as Live Desktop and Google Desktop take on a whole new level of importance when faced with the task of cataloging petabytes of information on your home PC. Because, let’s face it, you’ll never delete anything. You’ll take thousands of pictures with your digital camera and never delete any of them. You’ll take hours of high-def footage and never watch or edit them, but you’ll want to find something in them (with automated voice recognition and image analysis, of course). Every e-mail you get over your entire lifetime can be permanently archived.
What if you could get a catalog of every song ever recorded? That would probably require more than a few petabytes, even compressed, but we’re heading that way. I don’t think the amount of music in the world is increasing exponentially, is it? Applications like iTunes and Window Media Player, not to mention things like iPods, would have to have a critically-designed interface to handle the organization and searching for desired music. I think Windows Media Player 11 is incredible, but I don’t think it could handle more than about 100,000 songs without choking–has anyone approached any practical limits with it?
What about the total information in the world–that probably is increasing exponentially. Will we eventually have enough storage so that everyone can have their own local, easily searchable copy of the vast sum of human knowledge and experience? (Ignoring the question of why we would want to)
Let’s extrapolate this growth out 100 years to the year 2100. I won’t show the graph, but it approaches 1E+20 GB by the year 2100.
How do the economics of digital goods change when you can have an infinite number of them? It’s the opposite of real estate, an ever-diminishing good.
On my home PC, for the first time, I do have a lot of storage that isn’t being used. I have about 1 TB of storage, and about 300 GB free. I suppose I could rip all my DVDs, rip all my music at lossless compression (it’s currently all WMA / 192Kbps).
The rules of the game can change quickly when that much storage is available. It will be interesting to see what happens in the coming decades. Of course, all this discussion is completely ignoring the increasingly connected, networked world we live in.
del.icio.us Tags: hard drive,storage,infinity,searching
I made some minor updates to DiskSlicer. Mostly, some minor bug fixes, but also I added the much-requested ability to delete files directly from the program.
Even if the Internet connection goes out, your computer does not become a dumb brick. There were days these last few days where I didn’t bother turning it on. Then I realized all the things I could still do.
(My home Internet connection finally came back this morning. I’m bit upset that they didn’t figure it out earlier. It turned out that the first technician grossly misdiagnosed the problem. He put in an order for a new drop to be put in. Turned out it was just a broken modem. Why didn’t they try that earlier? Worse, why didn’t I think of it earlier. To be honest, I did think of it, but didn’t push it. Now I just need to get my money back from Comcast.)
Without further ado, here’s my suggestions for what to do when the Internet goes out:
On the computer:
Off the Computer:
Or just go to the library and use the Internet. I only did this a few times, despite it being within walking distance from where I live.
Technorati Tags: internet,comcast,off the grid,piano,boredom,computer,programming
Found The Nerd Handbook via Phil Windley. I sent it to my wife and told her she needs to read it. A highly-accurate depiction of nerds, I would say. At least in the generalities…
I’ve been meaning to write about this software for a while. When I started my current job, all software development was done by an outside contractor. I quickly took over, and that necessitated implementing a lot of tools and procedures to handle our large C++ and C# code base.
Choosing Subversion for source control was easy–free, open source, better than VSS and CVS.
Bug tracking software was a little harder. There are a lot of packages out there. I eventually decided on a great little package called BugTracker.Net. It’s written by a gentleman named Corey Trager who does it in his spare time. It’s a very simple system, and doesn’t provide a lot of the heavy-weight features of more complete packages, but if you’re a small team (like I’m in), then it could be perfect. I really appreciate Corey’s web-site, because he acknowledges that it’s not written with every scenario in mind. In fact, he even publicizes comparisons of his system with other popular tracking systems out there.
That said, there is a good degree of customizability in it, and it really was easy to setup, upgrade, configure, and customize.
Some of the features:
Suitable for tracking helpdesk customer support tickets as well as software bugs.
Sending and receiving emails is integrated with the tracker, so that the email thread about a bug is tracked WITH the bug.
Allows incoming emails to be recorded as bugs. So, for example, an email from your customer could automatically be turned into an bug/ticket in the tracker.
Allows you to attach files and screenshots to bugs. There is even a custom screen capture utility [screenshot] that lets you take a screenshot, annotate it, and post it as a bug with just a few clicks. (inspired by Fogbugz)
Add your own custom fields.
Custom bug lists, filtered and sorted the way you want, with the columns that you want.
You can display bugs of a certain priority and/or status in a different color, so that the most important items grab your attention.
Configure different user roles to see different lists of bugs. For example, a developer might see a list of open bugs. A QA analyst might want to see a list of bugs ready for testing.
(and more…)
Like I said, if you’re a small team that just needs to coordinate on issues, this platform could be perfect.
(BTW, this is not a sponsored post–I just want to point out some software that I like).
Another one of those lessons learned posts. I know I’m supposed to merge changes across branches often to minimize the pain, but I didn’t do it.
Here’s the scenario: We’ve got 3 development branches: 6.3, 6.4, and 7.0 (the trunk). 6.3 and 6.4 are technically maintenance branches because we didn’t anticipate needing to them, but we are. Here’s where it gets funny. 6.4 is actually a branch off of 7.0 with some new features removed. 6.4 is the code base converted to handle unicode. 6.3 is the current development version, and it’s features need to be merged into 6.4 These two branches are rather divergent in places. It’s been months since the branches were synchronized. In addition to 20 conflicted files, the 13 localized resource DLLs can’t automatically be merged because their location changed. Yeesh…
So now I’m spending all day using DiffMerge to do these files. Not a fun day…
Lesson learned. Do frequent merges.
At least it’s Friday. Tomorrow, my wife and I are heading down to North Carolina to visit my grandmother before she heads to California for Christmas.
By the way, still no Internet at home. Comcast says it could be 28 days before the local construction company gets around to installing the new drop to our home. I’ve been getting a lot of piano practice and reading in.
We have another sponsor! MyChoyce.com is a free dining guide for the San Francisco area. And wow. It’s nice. I am really wishing something like this existed for the Washington, DC metro area. The site is attractive, easy to use. And they have menus! Awesome.
You can search and filter by food, services, location, price. I’ve used a few restaurant locaters, with varying results, but so far I like this one the best. If you live in the bay area, check them out. If you’re a restaurant owner–I would get onto this site fast.
Thanks to them for their sponsorship, and if you know somebody who would like a little bit of extremely affordable publicity, send them to BuyMeALego.com!
![[screenshot]](http://ifdefined.com/bugtracker_screen_capture.jpeg){kind=link}