This is part two of my series on fast searching/filtering of text using C#.
In the previous article, we developed the filtering interface, built up a testing framework and implemented a naive indexer. For many purposes, that indexer performs more than adequately. Still, there are other possible implementations that might work better (or not…let’s wait and see).
SubString Indexer
In this installment, let’s develop something based on hash tables. With O(1) look-up time, they could be the ticket to blazing fast lookups.
We reuse the same internal structure as the NaiveIndexer, except I’ve changed it to a class. It needs to be reused many, many times for the same value so it’s much more efficient to share the object around instead of make copies:
1: private class IndexStruct
2: {
3: public string key;
4: public T val;
5:
6: public IndexStruct(string key, T val)
7: {
8: this.key = key;
9: this.val = val;
10: }
11: };
The fields are thus:
1: private int _maxKeyLength = 999;
2: private Dictionary<int, List<IndexStruct>> _hashes;
Notice again that we still don’t have to keep track of sort order in the IndexStruct. This is because down at the bottom of the data structure, all the data is still stored in List<> objects. I’m still breaking the law of abstraction by associating sort order to the order in which I add items, but…hey, it’s just an example.
Constructor
Let’s take a look at the constructor and figure out what the maximum key length is for, and a few other issues we have to handle:
1: public SubStringIndexer(int numItems, int maxKeyLength)
2: {
3: _maxKeyLength = maxKeyLength;
4: _hashes = new Dictionary<int, List<IndexStruct>>(numItems);
5: }
As you can see, the constructor takes two arguments.
The number of items is used to initialize the Dictionary<> ( a hash table class) to the number of items we can expect. If you know you’re hash table theory, you know that the size of a hash table should ideally be a prime number much larger than the number of items you want to insert. I have not bothered to do that here and experimentation did not show a significant benefit. Also, the hash table will automatically expand itself anyway for a certain load factor.
The maxKeyLength parameter is crucial. Since this indexer works by calculating substrings, it’s important to specify just how big those substrings can be. There’s a tradeoff here. The longer the maximum, the more substrings can be precalculated, and the faster the searches will be. However, you pay an enormous price in memory usage. We’ll see that price below when we run this example. I’ve chosen 3 as a fairly good balance between speed and space.
Helper Functions
Before we override our interface methods, let’s define some helper functions we’ll need. The first is something we’re familiar with:
1: private string RemoveUnneededCharacters(string original)
2: {
3: char[] array = new char[original.Length];
4: int destIndex = 0;
5: for (int i = 0; i < original.Length; i++)
6: {
7: char c = original[i];
8: if (char.IsLetterOrDigit(c))
9: {
10: array[destIndex] = c;
11: destIndex++;
12: }
13: }
14: return new string(array, 0, destIndex);
15: }
Just as with the naive indexer (in fact, with all the indexers), we need to strip out unimportant characters.
One of the most important functions we’ll need is something to generate substrings given a key.
1: private List<string> GetSubStrings(string key)
2: {
3: List<string> results = new List<string>();
4:
5: for (int start = 0; start < key.Length; start++)
6: {
7: /*get maximum length of substring based on current
8: * character position (constrain it to within the string
9: * and less than or equal to the maximum key length specified
10: * */
11: int lastLength = Math.Min(key.Length - start, _maxKeyLength);
12:
13: /* Get each substring from length 1 to lastLength
14: */
15: for (int length = 1; length <= lastLength; length++)
16: {
17: string sub = key.Substring(start, length);
18: if (!results.Contains(sub))
19: {
20: results.Add(sub);
21: }
22: }
23: }
24: return results;
25: }
GetSubStrings returns a list of all substrings of length 1 to _maxKeyLength. If you think about it, you can see why limiting this number to a small number is a good idea. If you have thousands of different keys, each of a fairly sizable length, you will generate thousands and thousands of unique substrings, not to mention how long it will take (a very long time).
Now let’s look at how this indexer works.
Overview
Here’s the way it works. Each substring of a key is converted to a hash number, which is the index into the hash table. The hash of the substring is used instead of the substring itself to avoid storing the substrings in the hash table’s list of keys–just for memory reasons.
The value of each slot in the table is a list of items. Lookup works by first narrowing down the list by doing a hash lookup on the filter text, then doing a linear search through all the items returned from the hash table. We’ll see the details below.
AddItem
1: public void AddItem(string key, T value, UInt32 sortOrder)
2: {
3: string toAdd = key.ToLower();
4:
5: toAdd = RemoveUnneededCharacters(toAdd);
6:
7: List<string> subStrings = GetSubStrings(toAdd);
8: IndexStruct indexStruct = new IndexStruct(toAdd, value);
9: foreach (string str in subStrings)
10: {
11: List<IndexStruct> items = null;
12: int hash = str.GetHashCode();
13:
14: bool alreadyExists = _hashes.TryGetValue(hash, out items);
15: if (!alreadyExists)
16: {
17: items = new List<IndexStruct>();
18: _hashes[hash] = items;
19: }
20: items.Add(indexStruct);
21: }
22: }
After normalizing the key (lower-case, alphanumeric), we get the valid substrings. For each of those, we calculate it’s hash and try to look it up in our hash table. If it doesn’t exist, we create a new list for that substring. Then we add the new entry to that list.
Lookup
Lookup is a little more complicated, but still straightforward enough.
1: public IList<T> Lookup(string subKey)
2: {
3: string toLookup = subKey.ToLower();
4: List<IndexStruct> items = null;
5: List<T> results = new List<T>();
6: int hash = 0;
7:
8: if (subKey.Length > _maxKeyLength)
9: {
10: /*
11: * If the substring is too long, get the longest substring
12: * we've indexed and use that for the initial search
13: */
14: toLookup = toLookup.Substring(0, _maxKeyLength);
15: hash = toLookup.GetHashCode();
16: }
17: else
18: {
19: hash = toLookup.GetHashCode();
20: }
21:
22: bool found = _hashes.TryGetValue(hash, out items);
23: if (found)
24: {
25: results.Capacity = items.Count;
26: foreach (IndexStruct s in items)
27: {
28: /*
29: * Have to check each item in this bucket's list
30: * because the substring might be longer than the indexed
31: * keys
32: */
33: if (s.key.IndexOf(subKey, StringComparison.InvariantCultureIgnoreCase) >= 0)
34: {
35: results.Add(s.val);
36: }
37: }
38: }
39:
40: return results;
41: }
We first convert the subKey parameter (what we’re searching on) to lower case to normalize it. If that text is longer than the maximum subkey we’ve indexed, we trim it down to match the maximum size. Then we calculate the hash code and see if it’s in our list. If it isn’t found, there are no results and we return the empty list.
If a list was returned, we still have to go search through the entire list and do string searches to make sure our entire subkey is present in the key before adding it to the result set.
(If we needed to be concerned about sort order, we would do another post-processing step and sort the results list by sortorder.)
Testing
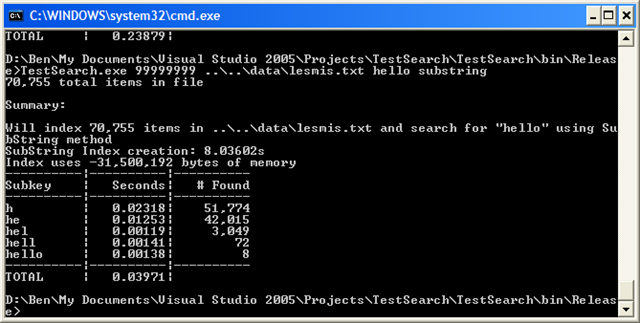
So let’s see how this works in practice by running it against the same lesmis.txt file.
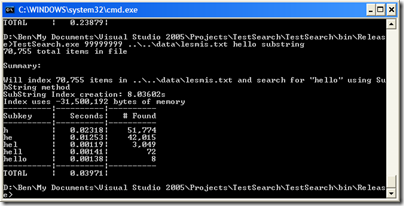
It’s nearly 3 times faster! But at what cost? It now takes about 8 seconds to create the index in the first place, and it uses 31 MB of memory. Ouch!
But I wonder….what if I run this against truly huge data sets…
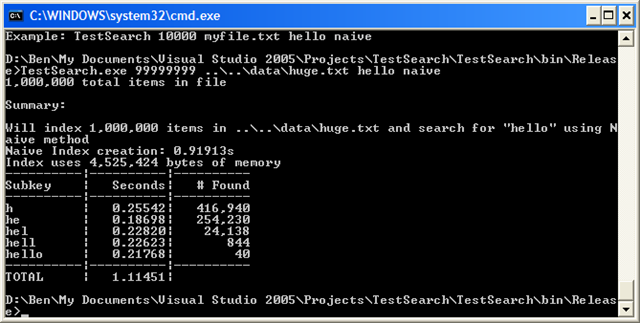
I create a million-line file out of various books available at the Gutenberg project. First, let’s run the naive indexer:
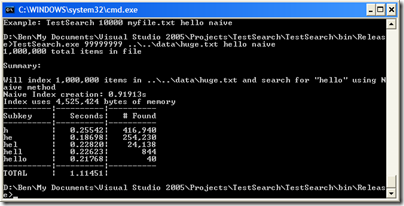
Now the naive way is taking over a second to do the search. What about our new substring indexer?
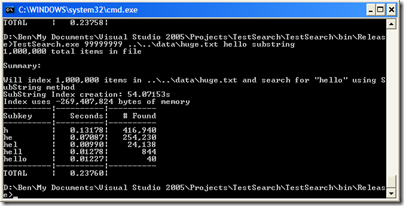
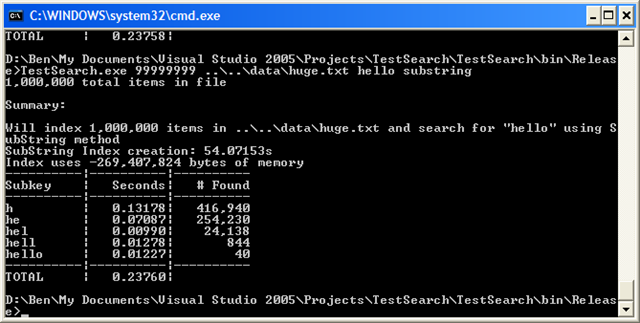
It takes nearly a minute to create the index, but lookups are now almost 5 times faster than the naive version–it definitely scales better. Well, except for that 270 MB index size!
Summary
So, this is an improvement in some ways, but it has some big costs (index creation time, index size). Next time, I’ll show yet another way that has some advantages.
Download sample project.