Even though I recently wrote about just using naive algorithms when they’re sufficient, it helps to know about other options and their characteristics. With that mind, I’m beginning a little series (4 parts planned–I’ll update this list as I go along) in C# documenting how I developed a few different approaches to doing fast (instant) filtering of large lists.
The article index:
- Getting Started – Indexing interface, test driver, and naive algorithm (this article)
- SubString indexer
- Trie indexer
- Efficient usage of ListView with filtering
Why Filtering?
I recently changed some internal apps at work do use filtering instead of column sorting of large listviews. It took a few days for the users to get used to it, but I’ve gotten comments back that it is amazingly better. The reason is that you are hiding all sorts of data you don’t need to look at. This is better in many cases than sorting, especially if you’re sorting 10,000 items. It’s also fairly intuitive for users to use.
The Requirements
Our indexer must have certain capabilities, so says me:
- Store any type of data
- Keys are strings
- Searches can be done on subkeys (i.e., if a key is “valjean”, doing a search for “lje” will work.
- Maintain sorted order, if desired
The Interface
The first thing we need to do is define a common interface that all our indexers will implement. This will make it very easy to swap them out when comparing different implementations.
Before showing the code, let’s discuss exactly what the indexer needs to do. Basically, the indexer has to accomplish two tasks:
- Index an item according to its key
- Lookup a key or subkey and return a list of items
We’ll assume that all keys will be strings because the point here is to do search, and search require strings. The actual values stored in the index, however, can be anything, so let’s make sure the interface supports generics.
Another potential problem is sort order. The internal index representation may not respect the order (for example, if a hash table were used, items are definitely not maintained in a sorted order). Our interface should provide a way to handle this.
It’s also possible that an indexer may want to know when indexing is finished so it can clean up any temporary data it may have created. Our first example will not use this, but we’ll put it in the interface now anyway.
So without further ado, here is our interface in all her glory:
1: interface IIndexer<T>
2: {
3: void AddItem(string key, T value, UInt32 sortOrder);
4:
5: IList<T> Lookup(string subKey);
6:
7: void FinishIndex();
8: }
Just three tiny functions. That’s all we need to get started.
Naive Indexer
With our interface designed we can quickly build a simple indexer. The algorithm for this one is brain-dead simple:
- Store key/value pairs in a list when added
- When a search is done, loop through all keys and do a substring lookup on each key. If substring is in key, add that value to a list. Return the list when done.
I did say this was naive.
Let’s start our implementation by deriving a new class from IIndexer<T>:
1: class NaiveIndexer<T> : IIndexer<T>
2: {
3:
4: }
No constructor is needed so let’s jump into the data structures required. For one, we need to store the key and value we’re adding, so let’s make a private structure to hold those together as well as a member variable list of structures to hold our data.
1: private struct ItemStruct
2: {
3: public string _key;
4: public T _value;
5: //public ushort _sortOrder;
6: };
7:
8: List<ItemStruct> _items = new List<ItemStruct>();
I include the sort order merely to show where it could go. I’ve left it commented it out in my implementation because I’m adding things in sorted order and the List<T> will keep things sorted for me. This is probably breaking the abstraction, but it’s easy enough for you to add it back in if you want. (Like I said, I wanted this to be as easy and light-weight as possible, so a leaky abstraction is acceptable in this case).
With these data structures, adding a new item is a piece of cake. We just create a new instance of the structure, set the fields, and add it to _items.
1: public void AddItem(string key, T value, UInt32 sortOrder)
2: {
3: string realKey = RemoveUnneededCharacters(key);
4: ItemStruct itemStruct = new ItemStruct();
5: itemStruct._key = realKey;
6: itemStruct._value = value;
7: //itemStruct._sortOrder = sortOrder;
8: //could insert into place of sortOrder, after a grow, if desired
9: _items.Add(itemStruct);
10: }
Woah, hold on! RemoveUnneededCharacters? Well, in my application I only wanted to index alphanumeric characters. This function strips all others from a string and returns the “real” key to use. Of course, during lookups, you’ll have to be similarly careful to sanitize the input to prevent searching on stripped characters.
1: private string RemoveUnneededCharacters(string original)
2: {
3: char[] array = new char[original.Length];
4: int destIndex = 0;
5: for (int i = 0; i < original.Length; i++)
6: {
7: char c = original[i];
8: if (char.IsLetterOrDigit(c))
9: {
10: array[destIndex] = c;
11: destIndex++;
12: }
13: }
14: return new string(array, 0, destIndex);
15: }
I think that’s a fairly efficient way of stripping characters that doesn’t rely on creating temporary strings, but if you have a better way, I’d love to see it.
Doing searches is similarly straightforward. We loop through each ItemResult in _items and see if our subkey is in the key. If it is, add it to a result list. After all are searched, return the result list.
1: public IList<T> Lookup(string subKey)
2: {
3: List<T> results = new List<T>();
4: foreach (ItemStruct itemStruct in _items)
5: {
6: if (itemStruct._key.IndexOf(subKey,
7: StringComparison.InvariantCultureIgnoreCase)>=0)
8: {
9: results.Add(itemStruct._value);
10: }
11: }
12: //Sort on results[i]._sortOrder, if desired
13: return results;
14: }
And that’s it! We now have a fully-functioning naive indexer. Now, let’s see how can test it and set the foundation for comparison of all the indexers we’re build.
Test Harness
I’m not going to include all of the code for the test harness here–you can find it in the sample code download. A simple description of it will suffice.
The test harness will take as input a filename, the number of items to index, what to search for (or filter on), and the indexing method. This will allow us to easily add other indexing methods as we develop them. Of course, being a simple test harness, there is no error-handling.
The items to be indexed will be lines from a text file. I’ve supplied the text of Les Misérables by Victor Hugo from Project Gutenburg, but you can use any text file you want (the larger the better). Les Misérables has about 70,000 lines. This is actually fairly small-medium.
Since, the reason for creating these indexers arose out of search-as-you-type functionality in one of my apps, the harness does progressive lookups on successive substrings of the key you type. I.e., if you do a search on “valjean”, it will first search “v”, then “va”, then “val”, etc.
Here is a screenshot of a sample run (click to enlarge):
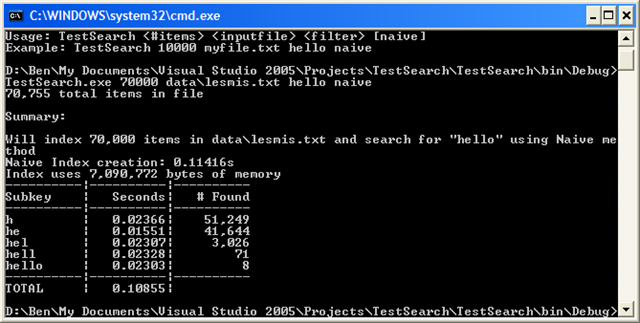
Optimization
I mentioned above that the need for this arose from doing filter-as-you-type functionality in one of my applications. This realization can lead to a major optimization, which I have not implemented in this example. If you’re doing successive searches, first searching for “v”, then “va”, then “val”, etc. You can cache the search filter and results of the previous query, and then on the next search instead of looking through the entire _items list, you can just look through the cached results instead. First, you just check to make sure that the previous filter is a substring of the current filter.
Summary
Next time, I’ll develop another indexing method that has some additional advantages and disadvantages. Using the test hardness, we can compare the different algorithms under different conditions. Stay tuned.
(I’m out of town this weekend, so comments will be approved after I return home)