In my current project, I’m using a custom ListView-like control to give my WinForms app a very rich interactive experience. This control does not implement mouse wheel scrolling like the Microsoft ListView implementation does so it was up to me to add it. You can use the knowledge in this article to implement full scrolling support in your own custom controls.
The custom component was derived from Control, which does provide the virtual function OnMouseWheel to handle vertical scrolling. The component also exposes the two scrollbars to manipulate.
First, take a look at Best Practices for Supporting Microsoft Mouse and Keyboard Devices, a good place to start learning about advanced mouse handling in Windows. Note that all of this requires IntelliPoint software to be installed.
Getting Started
Here’s some example code to get started with:
public class MyListView : GlacialComponents.Controls.GlacialList
{
}
Vertical Scrolling
As long as we’re talking about horizontal scrolling, let’s go ahead and discuss vertical scrolling with the mouse wheel. Add this override to the class:
protected override void OnMouseWheel(MouseEventArgs e)
{
base.OnMouseWheel(e);
}
It’s overriding from the Control class, not GlacialList. Assuming you’ve read the MS documentation referenced about, you’ll know that the scroll message includes the number of ticks, which is usually a multiple of 120. We need to accumulate this number and then scroll our view a corresponding amount.
First, some class variables:
private const int WHEEL_DELTA = 120;
private int _wheelPos = 0;
private int _wheelHPos = 0;
The _wheelHPos variable will be used later for horizontal scrolling. Then we modify our function to read like this:
protected override void OnMouseWheel(MouseEventArgs e)
{
base.OnMouseWheel(e);
_wheelPos += e.Delta;
while (_wheelPos >= WHEEL_DELTA)
{
ScrollLine(-1);
_wheelPos -= WHEEL_DELTA;
}
while (_wheelPos <= -120)
{
ScrollLine(1);
_wheelPos += WHEEL_DELTA;
}
Refresh();
}
After we accumulate the value, we scroll one line per WHEEL_DELTA value. (This code could certainly be optimized, but I think this version is clear.) After the scrolling we tell the view to refresh itself. The Best Practices recommend handling partial-line scrolling. In my case, since I just need to manipulate the scrollbars by one unit at a time it’s not applicable, but I encourage you to understand their sample code.
The ScrollLine() function will be application-dependent. For this class, it just needs to modify the scrollbars that were provided.
private void ScrollLine(int numLines)
{
vPanelScrollBar.Value = Math.Max(vPanelScrollBar.Minimum,
Math.Min(vPanelScrollBar.Maximum,
vPanelScrollBar.Value + numLines));
}
Horizontal Scrolling
That was fairly easy. Horizontal scrolling with the tilt-wheel is only a little more complex. This is because it’s not natively supported by the .Net Framework, and to a certain extent it’s not really supported on Windows XP. Full native support of the tilt wheel starts in Windows Vista.
Fortunately the IntelliPoint drivers fake it for us by sending our listview window a WM_MOUSEHWHEEL message anyway. Since .Net 2.0 doesn’t know what to do with this message (not sure about .Net 3.0), we need to take control of the message-handling and manually handle this message. The WndProc function is the function that handles all of this and it is virtual just for this purpose.
protected override void WndProc(ref Message m)
{
base.WndProc(ref m);
if (m.HWnd != this.Handle)
{
return;
}
switch (m.Msg)
{
case Win32Messages.WM_MOUSEHWHEEL:
FireMouseHWheel(m.WParam, m.LParam);
m.Result = (IntPtr)1;
break;
default:
break;
}
}
If you’ve done Win32 programming this will look very familiar, if a little out of place in .Net code. There are a few things going on here. First of all, you must call the base-class version of WndProc or your window will be very unexciting and quite broken. Take a look at WndProc for any control in Reflector to see all the work it’s doing.
Next, there is the Win32Messages class. This is an abstract class of my own creation that serves merely as a place to put definitions for Windows’ message definitions.
abstract class Win32Messages
{
public const int WM_MOUSEHWHEEL = 0x020E;//discovered via Spy++
}
So how did I know it was supposed to be have the value of 0x020E? Well, I could look in the Vista SDK where it’s defined, or I could read the Best Practices document referenced before. I didn’t find that page until after I had finished this implementation and I just used Spy++ to discover the messages coming to my window when I hit the tilt button:
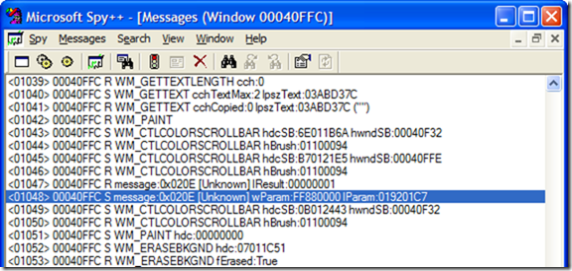
Before we get to the FireMouseHWheel function, notice that m.Result is set to 1. This is because the docs state that the message handling must return 1 to indicate to Intellitype that we’ve handled the message.
There are two versions of this function. One takes the raw WPARAM and LPARAM values from the message and the other takes more meaningful values. As you can guess, one should probably call the other.
public event EventHandler<MouseEventArgs> MouseHWheel;
protected void FireMouseHWheel(IntPtr wParam, IntPtr lParam)
{
Int32 tilt = (Int16)Utils.HIWORD(wParam);
Int32 keys = Utils.LOWORD(wParam);
Int32 x = Utils.LOWORD(lParam);
Int32 y = Utils.HIWORD(lParam);
FireMouseHWheel(MouseButtons.None, 0, x, y, tilt);
}
protected void FireMouseHWheel(MouseButtons buttons,
int clicks, int x, int y, int delta)
{
MouseEventArgs args = new MouseEventArgs(buttons,
clicks, x, y, delta);
OnMouseHWheel(args);
//let everybody else have a crack at it
if (MouseHWheel != null)
{
MouseHWheel(this, args);
}
}
I declare an event that takes the same type of arguments as the vertical MouseWheel handler above. The first FireMouseHWheel function converts wParam and lParam into the real values according to the specification given. I ignore the keys value and pass the others to the second function which calls my handler and also raises the event to give class consumers the opportunity to be notified as well.
To “crack” the values, I have some simple utility functions:
abstract class Utils
{
internal static Int32 HIWORD(IntPtr ptr)
{
Int32 val32 = ptr.ToInt32();
return ((val32 >> 16) & 0xFFFF);
}
internal static Int32 LOWORD(IntPtr ptr)
{
Int32 val32 = ptr.ToInt32();
return (val32 & 0xFFFF);
}
}
The OnMouseHWheel is very similar to its cousin for vertical scrolling:
protected virtual void OnMouseHWheel(MouseEventArgs e)
{
_wheelHPos += e.Delta;
const int pixelsToMove = 3;
while (_wheelHPos >= WHEEL_DELTA)
{
ScrollHorizontal(pixelsToMove);
_wheelHPos -= WHEEL_DELTA;
}
while (_wheelHPos <= -120)
{
ScrollHorizontal(-pixelsToMove);
_wheelHPos += WHEEL_DELTA;
}
Refresh();
}
The pixelsToMove variable is noteworthy because it’s hard-coded to 3. It is kind of arbitrary because it really depends on the application and how the scrollbars are used. I’ve set it to 3 as a good value for my application.
The ScrollHorizontal function is similar to ScrollVertical and is also application-specific:
private void ScrollHorizontal(int amount)
{
hPanelScrollBar.Value = Math.Max(hPanelScrollBar.Minimum,
Math.Min(hPanelScrollBar.Maximum - hPanelScrollBar.mWidth,
hPanelScrollBar.Value + amount));
}
Potential Issues
The Best Practices document states:
When an application receives a WM_MOUSEHWHEEL message, it is responsible for retrieving the characters-to-scroll user setting (SPI_GETWHEELSCROLLCHARS) by using the SystemParametersInfo API. This setting will not be available on Windows 2000 and Windows XP, so use the value of 1. IntelliType Pro and IntelliPoint will maintain a substitute value for the characters-to-scroll user setting and send the correct number of WM_MOUSEHWHEEL messages.
(Emphasis mine) Notice that last phrase. IntelliPoint can potentially send multiple WM_MOUSEHWHEEL messages for a single tilting action. This means that my strategy of refreshing on every message might not be entirely wise. It really depends on how long it takes to refresh the control. If it can be done smoothly and instantly, then this might not matter. Otherwise, you might need to come up with a way of accumulating ticks over multiple messages and scrolling all at once, perhaps after a timer expires. In my case, I think I’ll ignore this issue for now. I don’t really care if the control refreshes too often.
Have fun adding horizontal scrolling to your app!